How I Built a $500K Data Synthesis Pipeline for $1,000 in 30 Days with Claude Code
Between January 23rd and February 21st of this year, I vibe coded 88,000 lines of Python into a data synthesis pipeline that scraped 1,800+ universities and produced a dataset that even the Department of Education doesn't have — the actual cost of attendance of every graduate and professional degree in America, uncovering a $50+ billion funding gap that nobody has quantified yet — the kind of output that would have taken a team of 5 people 12-18 months to produce and cost $500K. Instead, I spent $967.08.
Powered by copious amounts of Cafe Bustelo, 16-hour work days, and Chinese takeout — this is the story of the most sleepless month of my life.
The tweet
It's mid-December 2025. The Christmas lull is in full swing, people are checked out at work. Me? I'm bored. My mind spiraling in an anxious doom loop with nothing to do. I'm waiting for my Alibaba shipment which is somewhere in the Pacific Ocean. I wonder... should I send my supplier a message just to get a "hello dear 🌹🌹🌹" or a "yes boss"? Nah. Instead I'm mindlessly scrolling Twitter. Then I see this:
I sit up in my chair. Like the kids say, I'm locked in. I'm clicking on Jason's tweet, reading the replies. How did he do it? I pull up Gemini and start investigating. I find a pattern. COVID-19 tests. PPP loans. It turns out government regulation can sometimes create a forced market dislocation. If you move fast, have the right skillset and team, there's a business on the other side.
Was there a modern equivalent, I wondered? I spent days digging, prompting Gemini like a maniac. Then I found it: the One Big Beautiful Bill Act, signed July 4, 2025. Buried in the bill was a provision eliminating Grad PLUS loans for all new graduate borrowers, effective July 1, 2026. Unlimited federal borrowing would be replaced with hard caps. All that displaced lending? It would have to be absorbed by the private sector. Why was this being done? My best guess was that tuition inflation had gotten out of control — since 2006 the government had guaranteed unlimited borrowing for students up to cost of attendance, and tuition predictably spiraled. Now they were pulling the plug.
By Christmas my Alibaba shipment was forgotten and I was stuck in my office planning my own affiliate business with Gemini as my chief strategist. By January 1st I had a comprehensive business plan laid out and 30+ niche domains purchased to capture the internet real estate of this regulatory change. Next, I needed to somehow collect the data that would power this business.
1,800+ different websites
The data I needed didn't exist. The Department of Education tracks who enrolls in graduate school via IPEDS, but they don't track what it actually costs. I'd have to collect it myself. From every university in the country.
If you've ever done web scraping, you know this is the hardest version of the problem: Deep Traversal with Heterogeneous Targets. Standard scrapers fail here because every university presents the data differently. University A puts tuition in a PDF. University B uses a dynamic dropdown. University C splits it across three different Bursar pages.
To get the cost of a single program at a single university you need to:
- Find the right page (buried under Financial Aid → Graduate → Current Year → Tuition & Fees)
- Figure out the billing structure (per credit? per semester? per year? per program?)
- Extract the rate, work out credits per term, terms per year, years to graduate
- Decompose the fees (base tuition, supplemental tuition, campus fees, health insurance, each billed differently)
- Find living expenses (off-campus, 9-month vs 12-month budget)
- Do all of this separately for resident, non-resident, and online students
Now multiply by 1,800+ universities. Every school is its own puzzle.
Claude Opus 4.6 had just come out. I wanted to see what it could do.
The seed phase
This was not my first rodeo scraping public data. The last time I did something like this, about 5 years ago, I discovered some data that, let's just say, should not have been public. But that's a story for another time.
The first two weeks in late January were manual. I used Gemini and Claude to scrape universities one at a time, building up a "seed" dataset of ~5,300 rows. I needed to understand the shape of the problem before I could automate it. What do fee structures actually look like? Where do universities hide costs? What are the common traps?
I felt like Michael Burry in The Big Short. Thousands of lines of Excel data. Residence status. Tuition. Fees. Program durations. Credit hours. I watched the movie twice during those two weeks. Not even joking. Ludacris "Money Maker" is still looping in my head.
By February 7th I had enough seed data and enough scar tissue to know exactly what to build.
The sprint
February 8th. I let loose with Claude Code and something clicked. Pure dopamine. 5 hours of sleep a night, 16-hour days. I couldn't stop.
The timestamps don't lie. I ran stat on every file after the project was done:
$36 for 919 universities in 45 minutes
This is the part I still can't believe.
I fed 11,908 raw documents (HTML pages and PDFs) to Claude Haiku 4.5. Not with templates or regex. Just: "read this page like a human researcher would, extract these fields into this Pydantic schema." It understood that "Tuition & Required Fees" at Texas A&M means something different than "Systemwide Tuition" at UC Berkeley. It figured out that a table labeled "Per Semester" at the University of Alabama actually shows annual rates. It caught that the International Student Services page at the University of Arizona shows non-resident rates masquerading as general rates.
The edge cases
The pipeline architecture isn't where the complexity lives. It's in the 82+ edge cases Claude and I caught in a living file called LEARNINGS.md. Some favorites:
Texas law has something called "Statutory Tuition" set at ~$50/credit. Sounds cheap, right? It's not the real rate. It's a legislative floor from the 1960s that nobody actually pays. The real cost is called "Designated Tuition" and it's 5-10x higher. The LLM didn't know this and extracted both, making every Texas school look way cheaper than it actually is.
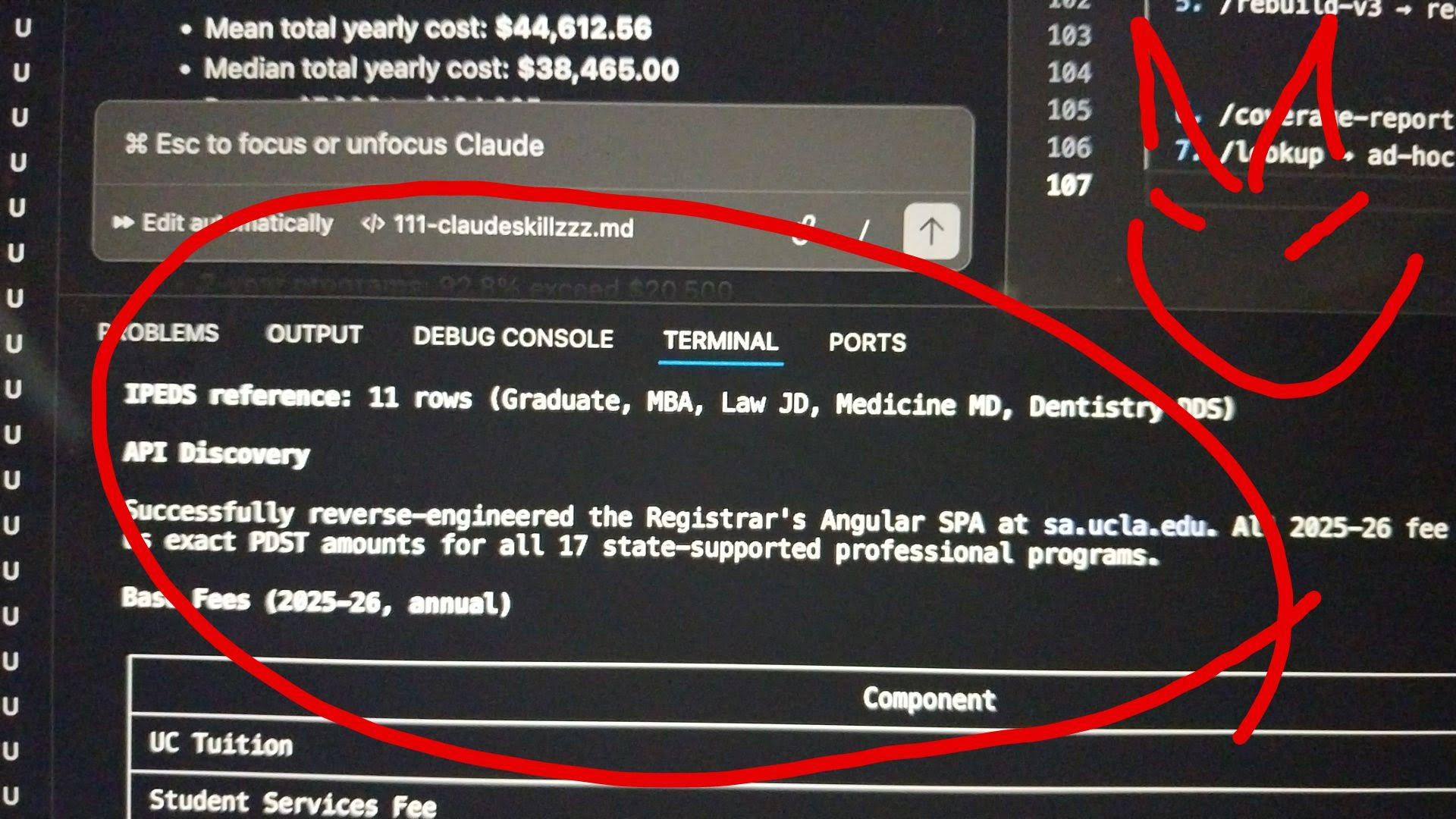
One university had all its tuition data locked inside an Angular SPA. I didn't ask Claude to do anything special here. On its own, it decided to reverse-engineer the Registrar's frontend, found the data endpoint buried in the JavaScript bundle, and pulled every rate table, every program, every residency status in a single request.
This is my favorite screenshot from the whole project. I just watched it happen in the terminal and thought: did it really just do that?
29 days later
The final dataset ended up at 7,300+ rows covering 1,800+ universities, with 22,000+ individual fee components broken out across 25+ degree types. Near-total coverage of every IPEDS-listed graduate institution in the country.
The report actually took more effort than the data collection. Claude could one-shot a draft, but I had to editorialize it over multiple passes, massage the language, verify numbers, and shape it into something that read like it came from a research institution. The big unlock was the fix-and-update cycle: find a problem, fix it, regenerate all 16 analysis files, re-sync 100+ inline statistics across the report, all in one sitting.
When I submitted the report to the US Copyright Office, the two-week adrenaline rush was wearing off and I was starting to fill with trepidation thinking about what I had just accomplished. I was, for all intents and purposes, living in the future.
On the product side, I fed Claude the report and enough context about the business and it was able to one-shot a landing page UI. The corporate website? Same thing. I had to go back and make edits but the core design was there from the first generation. Over the following weeks I built out multiple niche domain websites, each serving a specific graduate student vertical with interactive calculators and 5,000+ programmatic SEO pages.
The cost
Below is a breakdown of the cost using real numbers from my side and estimates from Claude for what it would have taken before LLMs existed.
| Me | 2021 estimate | |
|---|---|---|
| People | 1 | 4-5 (data eng, scraping specialist, policy analyst, frontend dev, QA) |
| Calendar time | 29 days | 12–18 months |
| Hours | ~200 | 3,000–4,500 |
| Cost | $967.08 | $200K–$640K |
The $967.08 covers everything: Anthropic API and Max subscription, Gemini Ultra, Haiku for bulk extraction ($36 for 919 universities), Sonnet for re-extraction (~$95), Vision for OCR, Serper.dev for search queries, and Vercel for hosting. Every tool, every API call, every subscription for the entire month. Under a thousand dollars.
After the project was done I got curious and ran an experiment. I gave the finished report to a completely separate Claude instance that knew nothing about the codebase and asked it to estimate how much the project cost to produce. It guessed 450–650 hours and $150K–$300K. When I told it the actual number:
"That's honestly staggering."
— Claude (blind estimate, Feb 19)
Yes, I'm quoting Claude's response verbatim.
I then asked Claude Code, the one that actually built the pipeline, to estimate the same thing. It said 500–800 hours with LLMs, or 3,000–4,500 hours without. It overestimated my actual hours by 3-4x because it assumed we were pair programming. We weren't. What actually happened was closer to delegation: I gave direction, reviewed what came back, and pressed enter on "yes." I wasn't writing code. I was managing an intelligence that writes code. That's the difference between using an LLM as a copilot (5x speedup) and using it as a workforce you direct (15–22x).
Here's what the compression actually looks like:
The calendar compression is the more startling one. There's that old saying: nine women can't make a baby in one month. You can't speed up sequential work by throwing more people at it. But what if you don't add people at all? I held the entire context in my head for a month straight. When I hit edge case #47, that knowledge immediately informed how I handled extraction #48. No handoff to a colleague. No Jira ticket. No waiting for someone to get back to me. Just me and Claude, in the same chair, with the same context, for 29 consecutive days.
So what?
Boredom is good, scrolling Twitter can sometimes be productive, and we will all be unemployed soon.
Maybe.
I'd bet there are people at consulting firms and hedge funds producing work at this scale with LLMs right now. But the economics haven't caught up. My guess is that engagements are still being scoped, staffed, and billed as if the old production function applies. Not out of dishonesty, but because that's how institutions work. Inertia is a hell of a drug.
And honestly, the incentives to stay quiet make sense. If you're employed, revealing this kind of throughput means your employer needs fewer of you. If you're a consultant, revealing the cost basis changes every conversation you have with a client. If you're an academic, revealing that the LLM did most of the heavy lifting raises uncomfortable authorship questions. I don't have any of those incentives. So here we are.
I don't think most people have internalized what's actually possible right now. I know I hadn't, before I sat down in that chair in January.